
ClickHouse JOIN dilemmas
In analytical databases, JOINs are often the silent killer of query performance.
Today I was diving deep into the different Clickhouse JOIN algorithms and want to share with you my summary.
There are 2 types of join algorithms: one is memory-bound, and the other is not memory-bound. The difference is how Clickhouse handles the right-side table in a JOIN. Clickhouse is a columnar data store that prefers to keep the data in RAM. However, if your dataset is larger than available memory, choosing the wrong JOIN algorithm can lead to “Memory Limit exceeded” warnings or even query failure.
When using the memory-bound join algorithms, Clickhouse requires the entire right table to fit in RAM. If the table exceeds the max_memory_usage setting( this setting controls how much memory a single query can use), the query will fail.
As a rule of thumb, you should always filter and aggregate the left-side table data first, and then put the smaller/dimension table on the right side of your join. Sometimes, to get predicates pushed down, before the join, you might need to put a left-side table filter and aggregation logic in a subquery and do the same for the right-side query as well. When you follow this pattern, your query performance can get to be 4 times faster.
ClickHouse Optimiser is getting better with every version, but if we let it choose an algorithm automatically, it will usually start with a Hash Join, and if the query hits the memory limit, it will switch to Partial Merge on the fly. Such a transition can consume extra CPU and might fail if the data structures are complex to sort.
Join Reordering: this is a known ability of data store optimisers to shuffle the order of tables involved in a join. In the recent versions, Clickhouse will analyse table statistics and can swap right and left tables. If, for some reason, it will not swap the tables and you put a 1TB table on the right and a 10MB table on the left, ClickHouse will try to load the 1TB table into RAM and likely will crash with an "Out of Memory" error.
It will swap tables for INNER JOINS, but not for LEFT JOINS and FULL JOINS.
Making sure you understand which table sizes and testing different join algorithms to see which one works faster for your query is better than relying on an optimiser and letting it switch join algorithms on the fly.
Memory-bound join algorithms:
- Hash: This is the default and fastest join algorithm. It builds a hash map of the right side table in memory. The left-side table is not fully loaded into memory. Clickhouse streams it by columnar chunks and applies a hash function to every join key. The left-side table can be indefinitely big, and join will work as long as the right table fits the RAM.
- Parallel Hash: Similar to Hash join, but splits the right-side table into multiple hash maps in parallel, and keeps all of them in RAM.
- As-of-join: This join type is used for joining time-series data when join keys do not match exactly but are close based on the timestamp sequence. This algorithm is very similar to Hash Join, where the right-side table (the reference table) is fully loaded into RAM, and the left-side table is being streamed through.
Join algorithms that are not memory-bound are able to join big tables that don't fit into the memory. They can spill data to disk or stream parts of the data into RAM.
- Partial Merge: this algorithm is some optimised version of a merge algorithm. It tries to avoid sorting the left-side table. It reads the right-side table, sorts it by join key, keeps it in memory or spills to disk, depending on the table size. Then, it reads the left-side table block by block and performs a merge with the right table. This algorithm can be incredibly efficient for tables that are already sorted and joined by PK.
- Grace Hash: This algorithm is similar to Hash but does not need the right-side table to fit into memory. It partitions the right-side table data into buckets; if a bucket is too large for RAM, it is written to disk and processed separately.
- Full Sorting Merge: this algorithm assumes that nothing is presorted, so it sorts first the right-side table by the join key, then sorts the left-side table (writes both results to a temporary place on the disk). Then performs a regular merge operation. Performance is usually the slowest of all algorithms.
- Direct: Used for Dictionaries ( data structures that store key/value data pairs in memory) or Join engine tables (table’s data is already organised in a hash map and located in RAM). This join algorithm looks up values directly without building a hash map.
Here is a nice chart from the Clickhouse academy course that shows joins comparison in terms of memory and execution time
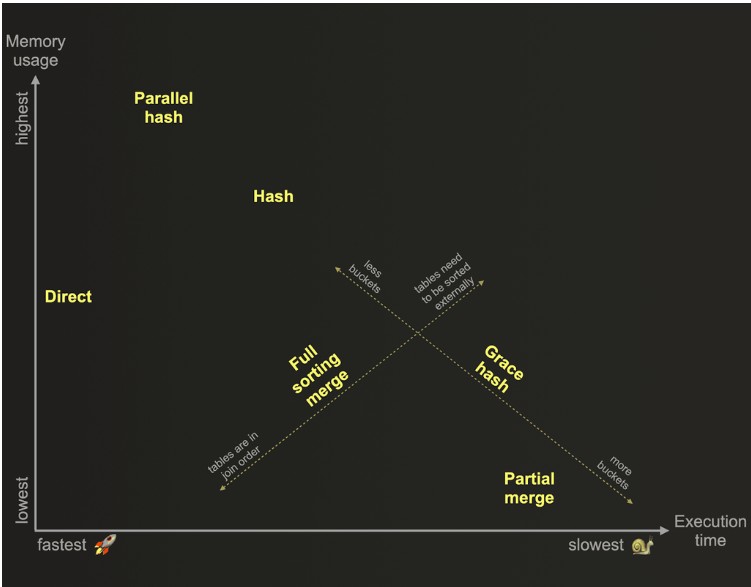
In general, try to avoid JOINs where possible and your queries will thank you.

Comments
No comments yet.
Leave a comment